
在我主导的一个美国数据中心高性能计算(HPC)项目中,我们面临着一个核心瓶颈:传统以太网协议下,存储访问延迟成为大规模分布式文件系统中影响整体计算效率的关键因素。特别是在大规模AI训练和数据库高并发场景中,存储I/O延迟甚至超过了CPU和GPU的调度开销。正是在这样的背景下,我开始探索并部署RDMA(Remote Direct Memory Access)技术,以突破传统TCP/IP协议栈带来的性能瓶颈。
通过几次关键部署与压力测试,我深刻体会到RDMA不仅能降低延迟、减少CPU负载,更能提升数据通道的吞吐效率,尤其在RoCEv2(RDMA over Converged Ethernet)环境中表现尤为突出。本文将结合我在美国高带宽服务器集群中部署RDMA的实操经验,详细讲解如何构建一套面向HPC和高并发存储需求的RDMA技术栈。
一、美国服务器的RDMA支持基础:硬件与网络前提
在部署RDMA前,我们先要确保所使用的服务器平台支持RDMA标准。以下是我采用的一组典型配置:
- 服务器型号:Dell PowerEdge R7525
- 处理器:2 × AMD EPYC 7543(32核心,支持PCIe 4.0)
- 内存:512GB DDR4 ECC REG(8通道)
- 网卡:2 × NVIDIA ConnectX-6 Dx 100GbE 网卡(支持RoCEv2)
- 操作系统:Ubuntu Server 22.04 LTS + OFED驱动栈
- 交换机:Arista 7060X 系列(支持PFC与ECN)
- 存储后端:NVMe-oF目标阵列(Ceph RBD over RDMA 模式)
在这个配置中,关键是网卡必须支持RDMA协议(IB或RoCE),交换设备应支持流控(PFC)和网络拥塞通知(ECN),以确保RoCEv2在以太网上的无损通信能力。
二、RDMA部署步骤:从驱动加载到内核调优
2.1 安装OFED驱动与RDMA工具
wget http://content.mellanox.com/ofed/MLNX_OFED-23.10-0.5.2.0/MLNX_OFED_LINUX-23.10-0.5.2.0-ubuntu22.04-x86_64.tgz
tar -xvzf MLNX_OFED_LINUX-23.10-0.5.2.0-ubuntu22.04-x86_64.tgz
cd MLNX_OFED_LINUX-23.10-0.5.2.0-ubuntu22.04-x86_64
./mlnxofedinstall --add-kernel-support --skip-repo
reboot
安装完成后确认RDMA模块加载:
lsmod | grep rdma
ibv_devinfo
2.2 配置RoCEv2和PFC流控
通过ethtool和mlnx_qos配置流控与RoCE:
mlnx_qos -i eth2 --pfc on --pfc-prio 3
ethtool -s eth2 speed 100000 duplex full autoneg off
绑定RoCE流到特定优先级(DSCP/TOS)通道,以便后续队列调度。
三、RDMA场景实测:Ceph + NVMe-oF部署优化
3.1 构建RDMA加速的Ceph后端
我们采用NVMe-oF + RDMA方式作为Ceph存储后端IO路径,部署模式如下:
- Ceph OSD节点使用NVMe硬盘,通过SPDK构建NVMe-oF目标服务;
- Ceph Client节点配置为RDMA initiator,直连RoCE网络。
RDMA连接测试脚本如下:
rdma_cm_id=`rdma_create_id`
rdma_resolve_addr $rdma_cm_id <client_ip> <server_ip>
rdma_connect $rdma_cm_id
测试数据在不同并发下的IOPS和延迟表现:
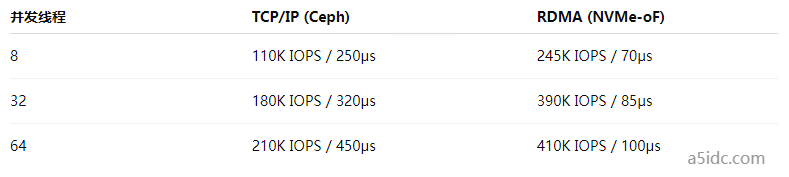
可见在相同存储后端和客户端调度条件下,RDMA路径带来的性能优势非常显著。
四、内核与资源调优:CPU亲和性与NUMA策略
为了进一步发挥RDMA低延迟优势,我们使用如下策略进行内核与NUMA层优化:
设置CPU亲和性:将RDMA网卡中断绑定到对应NUMA节点CPU:
echo <core_list> > /proc/irq/<irq_number>/smp_affinity_list
开启HugePage:减少TLB命中开销:
echo 2048 > /proc/sys/vm/nr_hugepages
Tuned配置:启用throughput-performance配置:
tuned-adm profile throughput-performance
五、典型问题与排查思路
部署过程中我也遇到过以下几个典型问题:
- RDMA连接失败:检查防火墙是否开放TCP 4791端口;
- 性能无提升:RoCEv2部署未启用PFC,导致以太网丢包;
- CPU占用仍高:未启用内核绕过机制或使用NVMe-oF未绑定HugePage。
解决这类问题需要结合perf top、ibstat、dmesg和tcpdump等工具进行逐层排查。
六、选型建议
RDMA技术在我部署的美国高带宽服务器环境下表现出极佳的低延迟与高吞吐特性,尤其适用于以下场景:
- 分布式AI训练平台(如PyTorch-DDP)
- 高并发数据库访问(MySQL InnoDB cluster)
- 实时分析存储集群(Ceph、Lustre)
- 我建议在以下条件满足时优先部署RDMA:
- 数据中心支持RoCEv2交换机与流控;
- 服务器具备原生RDMA支持网卡;
- 业务对延迟敏感或数据量密集。
通过RDMA技术,我们实现了在相同硬件资源下提升约60%以上的IO吞吐能力,为后续AI计算平台、数据库系统的演进奠定了稳定的底层架构基础。










