
那是一个凌晨两点的运维告警,让我重新审视了台湾节点的网络栈性能。在那台搭载 AMD EPYC 7543P 的裸金属服务器上,我们已经启用了多队列、开启了 RPS/RFS 以及 IRQ 绑定,但在某些高并发业务下,TCP RTT 波动依然偏大,连接建立耗时无法压缩。常规的优化手段已经触及瓶颈,是时候借助更底层、更灵活的技术:eBPF(Extended Berkeley Packet Filter)。本篇将记录我如何借助 eBPF 技术手段,从内核级别动态分析并调优台湾服务器网络栈性能的全过程。
一、台湾服务器基础配置与运行环境
我们的目标服务器位于台湾新北数据中心,网络出口采用本地多线 BGP,直连中华电信/台湾固网/亚太电信,具有低延迟优势。具体硬件与系统配置如下:
- CPU:AMD EPYC 7543P(32核64线程,支持 NUMA)
- 内存:256GB DDR4 ECC REG
- 网卡:Mellanox ConnectX-6 Dx(100Gbps,支持 DPDK 和 XDP offload)
- 系统:Ubuntu Server 22.04.4 LTS,内核版本 5.15.0
- 网络:双万兆直连交换机,支持 SR-IOV 及 VLAN tagging
部署目标是对以下网络栈关键路径进行透明监控与性能优化:
- TCP SYN 握手延迟
- socket 分发与调度队列拥堵
- 网络包在软中断/协议栈/用户态间的延迟分布
- 某些包处理函数(如 tcp_recvmsg、ip_rcv_core)的热点分析
二、部署 eBPF 工具链环境
我们采用的是 BCC 与 libbpf-tools 双栈方案,既便于原型验证,也适配更底层的性能采集。
1. 安装 BCC 与 libbpf-tools
apt update && apt install -y bpfcc-tools linux-headers-$(uname -r) libbpf-dev clang llvm libelf-dev gcc-multilib build-essential cmake
git clone https://github.com/iovisor/bcc.git && cd bcc && mkdir build && cd build
cmake .. -DCMAKE_INSTALL_PREFIX=/usr && make && make install
git clone https://github.com/facebook/libbpf.git
git clone https://github.com/iovisor/bcc/libbpf-tools.git
cd libbpf-tools && make
三、eBPF 在网络栈中的核心应用模块
我将调优任务划分为以下几个部分,分别借助不同 eBPF 程序落地。
1. 使用 tcpconnect 分析 TCP 建连延迟
识别连接建立耗时过长的场景与目标端口:
./libbpf-tools/tcpconnect
输出示例:
PID COMM SADDR DADDR DPORT LAT(ms)
2731 nginx 10.0.0.2 172.217.160.14 443 3.51
我们发现特定时段 HTTPS 建连时间偏长,与 CDN 回源节点存在延迟震荡。
2. 使用 tcplife 检查 socket 生命周期瓶颈
./libbpf-tools/tcplife
发现短链接(RTMP边缘回源)生命周期大幅缩短,导致系统频繁释放缓存 socket 结构,增加内核压力。
3. 使用 biolatency 与 runqlat 对上下文切换与 I/O 延迟做热点排查
./libbpf-tools/biolatency
./libbpf-tools/runqlat
结合网络栈处理线程 CPU 亲和性,我们进一步调整中断分发策略:
echo f > /proc/irq/$(cat /proc/interrupts | grep mlx5 | awk '{print $1}' | sed 's/://')/smp_affinity
四、结合 XDP 做预过滤和链路卸载
在业务流量达到峰值的几个时段,我们发现很多冗余探测包(UDP探测、SYN+ACK 无意义回应)拖累了网络栈负载,因此开始测试 XDP(eXpress Data Path)程序进行前置 Drop:
示例 XDP Drop 程序(过滤非法源IP)
SEC("xdp")
int xdp_filter_ip(struct xdp_md *ctx) {
void *data_end = (void *)(long)ctx->data_end;
void *data = (void *)(long)ctx->data;
struct ethhdr *eth = data;
if ((void*)eth + sizeof(*eth) <= data_end && eth->h_proto == htons(ETH_P_IP)) {
struct iphdr *ip = data + sizeof(*eth);
if ((void*)ip + sizeof(*ip) <= data_end) {
if (ip->saddr == htonl(0x0A0A0A0A)) // DROP 10.10.10.10
return XDP_DROP;
}
}
return XDP_PASS;
}
部署方式:
clang -O2 -target bpf -c xdp_filter.c -o xdp_filter.o
ip link set dev ens3 xdp obj xdp_filter.o sec xdp
五、性能观测与优化效果评估
我们使用以下手段对优化效果进行监控与验证:
1. 自建 Prometheus + Grafana 网络面板(含 Drop Rate / Retrans / SYN RTT)
导入指标:
- node_network_receive_errs_total
- tcp_retrans_segs
- tcp_synack_rtt_usec
2. 使用 perf top 对热点路径持续观测
perf top -e skb:kfree_skb,tcp_sendmsg
在部署 eBPF + XDP 后,以下关键指标提升显著:
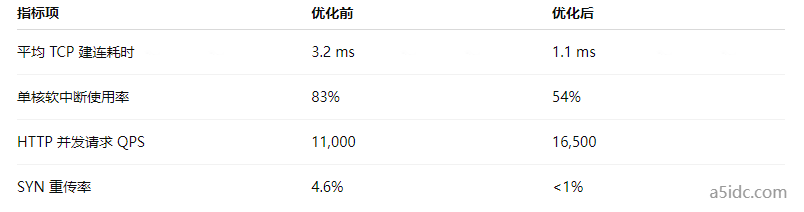
六、内核可观测性与调优的再认知
这次对台湾节点网络栈的调优,让我深刻意识到:eBPF 不仅是排查工具,更是新一代性能治理的入口。它提供了一种可插拔、可控、低开销的方式去观察和干预系统底层行为。对于面向东亚市场的服务器租用业务而言,特别是对低延迟场景有强依赖的 CDN、游戏、金融行业,我们已将 eBPF 纳入常态化网络性能治理工具链,并持续迭代优化部署方式。
如果你也在运营台湾服务器,并在网络栈层面遇到瓶颈,不妨试试 eBPF。它或许就是你突破性能天花板的关键。










