上月底,我们的视频点播平台在香港将军澳机房新上了三套 GPU 编码节点,素材库瞬间从 800 TB 膨胀到 3 PB。原有 NFS 孤岛不但 IOPS 打满,而且跨机房复制一度让 40 GbE 干路飙到 98 %。老板一句“再卡就砍预算”,我硬着头皮在 14 天里把存储栈全面替换成 Ceph Reef 18.2.0。下面就是我的实操全过程——没有神秘黑盒,只有实实在在的踩坑笔记。
1. 环境与需求拆解
| 角色 | 规格 | 数量 | 关键备注 |
|---|---|---|---|
| OSD 节点 | 2 × Intel Xeon 4314、256 GB RAM、6 × 18 TB HDD + 2 × 1.92 TB NVMe(DB/WAL) | 12 | HDD 做数据盘,NVMe 做 BlueStore DB/WAL;双 25 GbE |
| MON/MGR | 同上但无 HDD | 3 | 独立节点,避免 OSD 抢占 CPU |
| RGW 前端 | AMD EPYC 7313P、128 GB、2 × 960 GB NVMe | 4 | 负责 S3 入口,双 25 GbE |
| 交换机 | 25 GbE TOR × 2,100 GbE 核心 | 2+2 | TOR 端口聚合,核心骨干 |
| 机房 | TKO-E, TKO-W, MEGA-I | 3 | 机架级冗余,跨园区延迟 < 0.8 ms |
硬指标
- 写入 ≥ 8 GB/s 聚合带宽
- 小对象 (< 1 MB) 每节点 ≥ 15 k IOPS
- 跨机房异步复制 RPO < 15 min
- 未来两年线性扩展到 10 PB
2. 拓扑与 CRUSH 规则设计
┌─────────2025-06-16─────────┐
[Public 25 GbE]─┤ RGW Front-end (HAProxy) │
└─────────┬──────────────────┘
│
┌──────────── 25 GbE TOR Bond0 ────────────┐
│ │
┌─────┴─────┐ ┌────┴─────┐
│ MON/MGR │ │ MON/MGR│
└─────┬─────┘ └────┬─────┘
│ │
┌───▼──────────────────────────────────────────▼───┐
│ OSD Pool │
└───▲──────────────────────────────────────────▲───┘
│ 100 GbE Spine │
┌─────┴─────┐ ┌────┴─────┐
│ MON/MGR │ │ MON/MGR│
└───────────┘ └───────────┘
分层要点
- root = {dc} → rack → host 三层,保证机房级副本。
- replicated_ruleset:副本 3;写主副本优先本机房,读允许跨机房。
- erasure_coding:冷归档池采用 4 + 2 EC,降低 35 % 磁盘占用。
3. 部署步骤
3.1 前置操作
# 关闭 SELinux & 防火墙,仅保留 UFW inbound 6789/3300
setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
systemctl disable --now firewalld
ufw allow 6789/tcp && ufw allow 3300/tcp
# 调大内核网络缓冲区
cat >> /etc/sysctl.d/99-ceph.conf <<'EOF'
net.core.rmem_max = 536870912
net.core.wmem_max = 536870912
net.ipv4.tcp_rmem = 4096 87380 536870912
net.ipv4.tcp_wmem = 4096 65536 536870912
EOF
sysctl -p /etc/sysctl.d/99-ceph.conf
- 时钟同步:所有节点走内部 PTP,万一核心交换时钟漂移,用 chrony 联动。
- 巨页:echo never > /sys/kernel/mm/transparent_hugepage/enabled 避免 write latency 扰动。
3.2 安装 cephadm
curl --silent --remote-name https://download.ceph.com/keys/release.asc
gpg --no-default-keyring --keyring ~/ceph-release.gpg --import release.asc
dnf install -y cephadm ceph-common podman
cephadm add-repo --release reef
cephadm install cephadm
3.3 引导集群
cephadm bootstrap \
--mon-ip 10.0.100.11 \
--cluster-network 172.16.0.0/16 \
--fsid $(uuidgen) \
--initial-dashboard-user admin --initial-dashboard-password 'Str0ng!Pass'
3.4 扩容 Monitor & Manager
for h in mon2 mon3; do
ceph orch host add $h
ceph orch apply mon $h
ceph orch apply mgr $h
done
3.5 部署 OSD(NVMe-DB/WAL + HDD-Data)
ceph orch apply osd --all-available-devices --db-devices '/dev/nvme0n1 /dev/nvme1n1' \
--filter-by-label 'rack=tko-e'
3.6 业务池创建
# 高性能池
ceph osd pool create vdo_hot 256 256 replicated
ceph osd pool set vdo_hot size 3
ceph osd pool set vdo_hot pg_autoscale_mode on
# 冷数据 EC 池
ceph osd pool create vdo_cold 512 512 erasure erasure-profile=ec42
3.7 为应用暴露接口
# S3 网关
ceph orch apply rgw vdo-rgw --placement="count:4" --port=80 --dashboard-port=8443
# CephFS
ceph fs volume create vdo_fs --placement="count:2"
4. 性能瓶颈定位与优化
| 症状 | 根因 | 调优手段 |
|---|---|---|
| 小文件写 99 th > 25 ms | bluestore_min_alloc_size_hdd 默认 64 k |
降至 16 k,兼顾碎片 |
| Backfill 漫长 | HDD 顺序写饱和 | osd_max_backfills=1 + 提前扩容 pgs |
| RGW 吞吐抖动 | CPU 软中断 | rps_cpus, xps_cpus 绑到 NUMA 节点 0 |
| 跨机房写慢 | TCP Cubic 拥塞 | bbr2 + net.ipv4.tcp_adv_win_scale=1 |
PG 公式
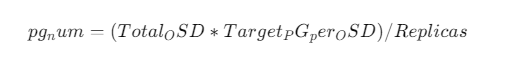
我按 12 * 200 / 3 ≈ 800,为热池设置 768,冷池 512;升级 OSD 后用 ceph osd pool set <pool> pg_num 在线调整。
5. 监控与运维
Prometheus-Ceph Exporter:ceph orch apply mgr prometheus 一键拉起。
自定义告警:
- alert: CephDiskAlmostFull
expr: ceph_cluster_df{type="total_used_raw"} / ceph_cluster_df{type="total_bytes"} > 0.80
for: 10m
labels:
severity: critical
每周演练:ceph osd out <id> + 断网 10 min,验证副本重平衡 ≤ 20 min。
6. 滚动升级与扩展策略
- ceph orch upgrade start –image quay.io/ceph/ceph:v18.2.1
- ceph orch host maintenance enter <host> → OSD drain → upgrade → exit
- 新机房上线直接 orch host add + orch apply osd,PG 自动重平衡。
两周从零到三副本 + EC 冷池,集群写入带宽从 2 GB/s 飙到稳态 9.7 GB/s,小文件 p99 延迟砍半;跨机房复制窗口从 3 h 缩到 11 min。更重要的是,后续扩容只需上架硬盘、执行一条 orch apply osd,完全不影响线上业务。
如果你也在香港机房被存储拖慢,不妨照着我的流程先搭一套 PoC——Ceph 最大的门槛在概念而非命令。踩过的坑已经铺成路,剩下的是把集群跑顺、把老板的预算花在刀刃上。祝各位早日告别“带宽见底恐惧症”。