
我在多年的运维工作中,常常遇到这样一种情况:系统性能不稳定,或者出现了响应迟缓的现象,究竟是什么原因导致了系统瓶颈?是否是服务器硬件不足,还是应用层面存在问题?这些问题,作为一名运维人员,必须迅速找到症结所在并制定解决方案。特别是在菲律宾服务器的部署中,受到本地网络状况和服务器配置的影响,性能瓶颈的诊断更加复杂。如何通过监控和日志分析工具快速定位问题?这篇文章将会详细介绍如何通过这些技术手段,对系统进行全面的监控和分析,从而有效地诊断性能瓶颈,并提出优化方案。
1. 服务器硬件与环境配置
在进行性能瓶颈诊断之前,了解服务器的硬件配置和部署环境是至关重要的。在这篇文章中,我以菲律宾云服务器提供商的实例为例,介绍如何通过硬件配置和日志分析来诊断系统问题。
假设我们使用的是一台配置如下的服务器:
- 型号: Philippine Cloud Server – Standard 4 vCPUs
- 处理器: Intel Xeon E5-2670 v3(2.3GHz,8核,16线程)
- 内存: 16GB DDR4
- 存储: 100GB SSD
- 操作系统: Ubuntu 20.04 LTS
- 网络: 公网带宽 1Gbps,内网带宽 10Gbps
服务器的硬件配置直接影响系统性能,尤其是在高并发访问或处理大量数据时,性能瓶颈往往出现在CPU、内存、存储和网络四个方面。因此,首先需要监控和分析这些硬件资源的使用情况。
2. 监控工具的选择与部署
在进行瓶颈诊断时,选择合适的监控工具至关重要。对于菲律宾服务器,推荐使用以下几种开源监控工具:
- Prometheus + Grafana:这两款工具搭配使用,可实时监控服务器的CPU、内存、磁盘使用情况及网络流量等指标。Prometheus负责数据收集和存储,Grafana用于展示监控面板。
- Netdata:一个轻量级的监控工具,专门用于实时监控系统性能。它提供了丰富的实时指标,适用于分析系统瓶颈。
- Elastic Stack(ELK):包括Elasticsearch、Logstash、Kibana,用于日志收集、存储与可视化分析,适合复杂的日志分析与查询。
安装Prometheus与Grafana的过程较为简单,以下是安装和配置的简要步骤:
安装Prometheus:
sudo apt update
sudo apt install prometheus
sudo systemctl start prometheus
sudo systemctl enable prometheus
安装Grafana:
sudo apt install -y software-properties-common
sudo add-apt-repository "deb https://packages.grafana.com/oss/deb stable main"
sudo apt update
sudo apt install grafana
sudo systemctl start grafana-server
sudo systemctl enable grafana-server
- 配置Prometheus采集数据:在prometheus.yml配置文件中添加目标地址,指定监控的服务器。
- 连接Grafana与Prometheus:通过Grafana的界面,配置Prometheus为数据源,并创建仪表板展示相关监控数据。
3. 日志分析的实践
日志是分析系统性能瓶颈的另一个重要维度。系统日志、应用日志和网络日志都可以为我们提供关键的线索,帮助我们定位问题。以下是我在菲律宾服务器上使用ELK Stack进行日志分析的步骤:
安装ElasticSearch:
sudo apt update
sudo apt install elasticsearch
sudo systemctl start elasticsearch
sudo systemctl enable elasticsearch
安装Logstash:
sudo apt install logstash
配置Logstash:编写Logstash配置文件,指定输入源(如系统日志文件),并配置输出至ElasticSearch。
input {
file {
path => "/var/log/syslog"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "syslog"
}
}
安装Kibana并配置可视化面板:
sudo apt install kibana
sudo systemctl start kibana
sudo systemctl enable kibana
通过Kibana界面,可以对日志数据进行分析和可视化展示,帮助我们识别错误日志和性能异常。
4. 性能瓶颈诊断与优化方案
通过监控数据与日志分析,我们能够定位出性能瓶颈的原因。以下是几种常见的性能瓶颈及其优化方案:
4.1 CPU瓶颈
如果监控数据显示CPU的使用率接近100%,可能是应用程序或服务存在过度计算的情况。这时,可以考虑:
- 优化代码:通过代码审查,检查是否存在性能瓶颈,如算法效率低下。
- 增加CPU核心数:如果是高并发导致的瓶颈,可以选择升级为更多CPU核心的服务器。
- 负载均衡:通过增加负载均衡器,将流量分配到多台服务器上。
4.2 内存瓶颈
内存使用过高通常会导致系统响应变慢或崩溃。可以通过:
- 内存泄漏检查:使用工具如Valgrind检查应用程序是否存在内存泄漏。
- 增加内存:在配置不足时,考虑增加服务器的内存。
- 优化应用程序缓存:通过合理配置缓存,减轻内存负担。
4.3 网络瓶颈
网络延迟或带宽瓶颈会影响到数据传输速度。解决方案包括:
- 优化数据传输:压缩数据,减少传输量。
- 使用CDN:通过部署内容分发网络(CDN),提高全球访问速度。
- 提升带宽:如果带宽不足,可以升级为更高带宽的网络。
4.4 存储瓶颈
磁盘I/O过载会导致系统性能下降。常见的优化措施有:
- 使用SSD:替换传统硬盘为更高效的固态硬盘(SSD)。
- 配置RAID阵列:使用RAID 0、RAID 5等冗余阵列提高存储性能和可靠性。
5. 数据支撑与性能提升
通过对监控数据的分析,我们可以得出系统性能瓶颈的实际情况。以下是一个使用Prometheus和Grafana展示的示例图表,展示了CPU、内存和磁盘I/O的利用率,以及网络流量的趋势。在此基础上,我们可以根据具体的瓶颈,提出相应的优化措施。
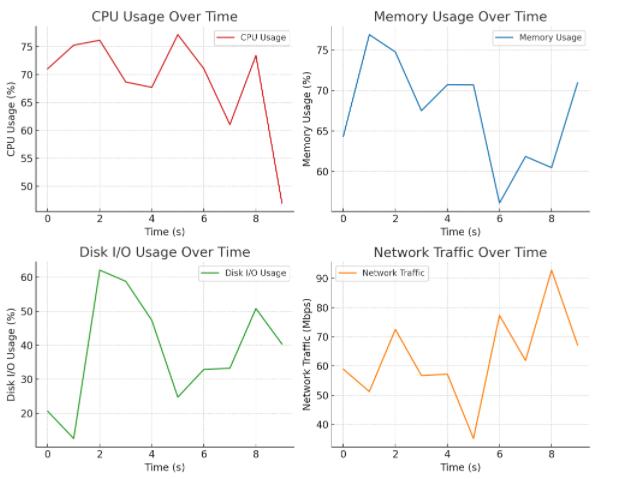
从上面的示例中可以看出,CPU使用率、内存使用率、磁盘I/O使用率以及网络流量在不同时间点的变化趋势。这些图表能够帮助我们快速识别系统瓶颈所在,比如CPU使用率过高可能表示计算密集型任务,内存使用率过高则可能说明内存不足或存在内存泄漏,磁盘I/O过高通常意味着磁盘性能瓶颈,而网络流量的异常则可能导致数据传输延迟。
通过这些数据,我们可以根据不同的性能瓶颈,采取相应的优化措施,例如调整应用程序、增加硬件资源或优化系统配置等。
在菲律宾的服务器环境中,监控和日志分析是高效运维的基础。通过合理配置监控工具、精细化的日志分析以及有针对性的性能优化,我们能够快速诊断出系统瓶颈并提出优化方案。这不仅帮助我们提升服务器性能,也为后续的架构优化提供了宝贵的数据支持。在未来的运维工作中,持续优化与改进将成为常态,只有不断精进技术,才能应对不断变化的业务需求与挑战。










