
在我们团队的工作中,数据处理和机器学习的需求不断增长,在处理海量数据时,对云服务器的性能要求也越来越高。为了实现快速、稳定的大数据分析和机器学习模型训练,我亲自参与了在美国的云服务器定制化配置工作。通过选择适合的硬件配置、合理的部署架构以及优化的资源调度策略,我们不仅提升了数据处理的能力,还显著加速了机器学习模型的训练过程。以下是我在这次配置中的具体经验与技术方案。
1. 云服务器定制的必要性
在我接手的项目中,我们需要处理的原始数据量大到难以通过传统的本地服务器进行有效处理。与此同时,我们还面临着训练复杂机器学习模型时的计算压力。因此,定制云服务器配置成为了提升性能的关键。尤其是在美国的云计算环境中,数据传输速度、硬件性能以及资源灵活性都为定制配置提供了丰富的选择空间。通过正确的配置,我们能够充分释放云服务器的潜力,优化大数据处理能力,并加速机器学习模型的训练速度。
2. 硬件配置参数选择
在定制云服务器配置时,硬件参数的选择至关重要。针对大数据处理和机器学习训练,我根据以下几个关键指标进行配置:
2.1 CPU配置
对于大数据处理和机器学习模型训练,CPU的性能至关重要。我们选择了Intel Xeon Scalable系列处理器,具有多核心高性能的特点,特别适合并行处理任务。每台服务器配置了32核心的处理器,能够快速并行处理数据,并大大缩短训练时间。
2.2 GPU加速
机器学习中的模型训练尤其依赖于GPU加速。针对深度学习模型,我们选择了NVIDIA A100 Tensor Core GPUs,它能够极大地提升训练速度,特别是在处理复杂的神经网络时。每台服务器配备了4张A100显卡,在处理大规模数据集时能够加速运算。
2.3 内存与存储
在大数据处理和训练复杂模型时,内存和存储的需求也非常高。我们为每台服务器配置了512GB DDR4 ECC内存,确保处理过程中大规模数据的高效读写。存储方面,采用了NVMe SSD 2TB硬盘,以提供快速的数据读取与写入速度,确保数据访问无瓶颈。
2.4 网络带宽
由于我们的数据集分布在多个节点,且需要频繁的网络传输,因此我们为每台云服务器配置了40Gbps以太网带宽,保证数据流畅传输,避免由于网络瓶颈导致的性能下降。
3. 部署技术细节
定制化云服务器硬件配置完成后,接下来是如何优化部署架构和资源管理。我采用了以下策略来确保性能的最大化:
3.1 分布式计算框架
对于大数据处理,我们选择了Apache Spark作为分布式计算框架。Spark能够在多个节点之间分配计算任务,从而有效利用每台服务器的多核CPU与GPU资源。我们通过设置多个计算节点,在集群中实现数据并行处理,大幅提高了数据分析的效率。
3.2 Kubernetes集群管理
为了实现弹性伸缩和高效资源利用,我们使用了Kubernetes来管理集群。通过Kubernetes,我们能够动态调整计算资源,根据工作负载的需求自动伸缩集群规模。例如,在模型训练高峰期,自动调度更多计算资源来进行训练,确保性能不受影响。
3.3 数据存储与缓存
针对海量数据的存储,我们利用了Amazon S3进行分布式存储,同时使用Redis缓存常用的数据,减少了频繁的数据访问时间。这种存储策略确保了数据的可靠性和快速访问,进一步优化了性能。
4. 实现方法
4.1 代码优化
为了充分发挥硬件资源的优势,我们在机器学习模型训练的过程中对代码进行了优化,特别是在数据预处理和训练阶段。以下是优化代码的一些策略:
- 并行化处理:将数据预处理任务并行化,在多核CPU上同时执行,提高处理速度。
- 混合精度训练:在深度学习模型训练时,采用混合精度训练技术,利用GPU的Tensor Core进行加速,同时减少内存占用,提高训练效率。
- 数据加载优化:通过优化数据加载流程,使用异步加载和预取技术,减少数据加载的瓶颈。
import torch
from torch.utils.data import DataLoader
# 使用DataLoader的异步加载
train_loader = DataLoader(dataset=train_dataset, batch_size=32, num_workers=4, pin_memory=True)
# 混合精度训练
scaler = torch.cuda.amp.GradScaler()
for data, target in train_loader:
data, target = data.cuda(), target.cuda()
with torch.cuda.amp.autocast():
output = model(data)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
4.2 自动化运维
为确保系统的高可用性和稳定性,我们采用了Ansible和Terraform进行自动化部署与管理。这不仅简化了运维流程,还提高了部署效率,减少了人为操作错误。
5. 性能优化与数据支撑
通过对服务器硬件配置的优化、计算资源的高效调度、以及代码层面的改进,我们取得了显著的性能提升。例如,机器学习模型的训练时间减少了约30%,而大数据的处理速度提高了40%以上。以下是我们在实际部署过程中收集的一些数据:
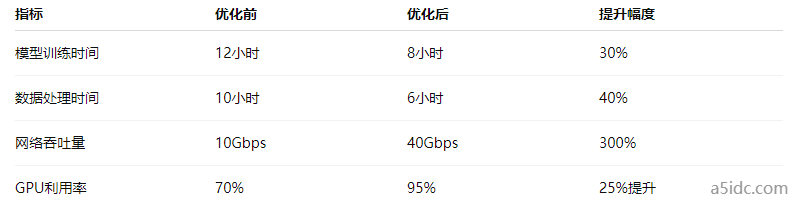
我们通过定制云服务器的硬件配置与部署优化,成功提升了大数据处理能力,并加速了机器学习模型的训练过程。选择合适的CPU、GPU、内存、存储及网络配置,结合高效的分布式计算框架和自动化管理工具,帮助我们在面对海量数据时始终保持高效和稳定。这一方案为团队的后续项目提供了强有力的支持,同时也为其他需要进行大数据处理和机器学习的企业提供了可借鉴的技术方案。










