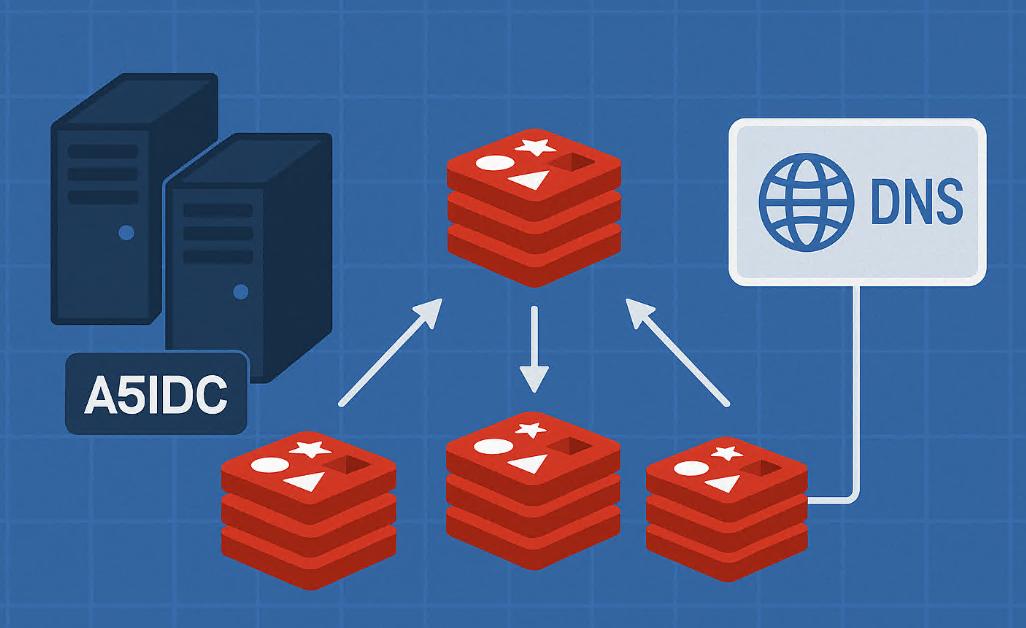
几个月前,我在台湾数据中心为一家对延迟极为敏感的在线金融平台部署Redis高可用架构。由于该平台的交易引擎和实时数据流都严重依赖Redis服务,因此在架构设计阶段,我们决定引入哨兵(Sentinel)机制来实现主从切换自动化,并配合内部DNS系统实现客户端连接的无感知切换。这个过程中,我踩过不少坑,最终在实战中总结出了一整套可维护、低延迟的高可用部署方案。以下是我完整的实操过程和经验提炼。
一、台湾服务器与网络基础环境
在台湾,我们选择部署于A5IDC台北核心机房,具备BGP多线网络、专线跨境带宽,以及极低的骨干延迟。部署环境的核心硬件参数如下:
- 主节点服务器:AMD EPYC 9354P,32核64线程,256GB DDR5 ECC内存,2×3.84TB NVMe 企业级SSD,双口万兆
- 从节点服务器:3台相同配置,分别部署于不同机柜以提升故障域隔离
- 哨兵节点服务器:最小规格为Intel Xeon E-2236,64GB内存,SSD存储,部署于多个逻辑区域
- 网络架构:内部VLAN隔离,Redis集群通信使用专用子网,哨兵使用独立逻辑隔离的管理平面
二、Redis主从集群部署方法
1. 安装与初始化
所有节点系统均使用 Ubuntu 22.04 LTS。我们首先在每台Redis节点上安装相同版本的Redis(推荐使用 >=7.0)。
apt update && apt install redis-server -y
在主节点中配置如下:
port 26379
sentinel monitor mymaster 10.0.0.1 6379 2
sentinel auth-pass mymaster your_redis_password
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1
在从节点中增加以下设置:
replicaof 主节点IP 6379
masterauth your_redis_password
2. 启动验证
启动所有Redis实例后,使用 redis-cli 工具逐个验证主从同步状态:
redis-cli -a your_redis_password INFO replication
确认 role:slave、master_link_status:up 正常后进入下一阶段。
三、哨兵机制配置
哨兵的关键作用是监控主节点状态并在主节点不可用时自动促发主从切换。
1. 基础配置
每台哨兵节点部署Redis Sentinel(可以与Redis服务分离):
cp /etc/redis/sentinel.conf /etc/redis/sentinel.conf.bak
配置文件关键内容如下:
port 26379
sentinel monitor mymaster 10.0.0.1 6379 2
sentinel auth-pass mymaster your_redis_password
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1
参数说明:
- mymaster:集群主节点名称
- 10.0.0.1:初始主节点地址
- 2:最少几个哨兵认为主节点不可用后才发起切换
2. 启动哨兵服务
redis-server /etc/redis/sentinel.conf --sentinel
3. 网络通信验证
确保以下端口在所有节点之间开放:
- Redis通信端口:6379
- Sentinel控制端口:26379
- 使用 telnet 或 nc 工具进行连通性测试。
四、DNS与客户端连接自动切换方案
1. 传统哨兵连接方式的局限
使用 sentinel get-master-addr-by-name 方式可动态获取主节点地址,但对客户端接入层不友好。多数客户端不具备哨兵协议支持,尤其是基于中间件或配置中心统一管理的架构。
2. 引入内部DNS映射机制
我们搭建了 内部DNS服务器(CoreDNS),配合 Redis-Sentinel-Exporter 脚本周期性检测哨兵状态并自动更新DNS记录,实现如下效果:
redis.service.local 永远指向当前主节点IP
哨兵切换后,DNS记录在3秒内同步变更
CoreDNS配置片段如下:
redis.service.local {
hosts {
10.0.0.1 redis.service.local
fallthrough
}
}
脚本定时更新该 hosts 区块,配合短TTL(如5秒),客户端无感知切换。
3. 客户端配置建议
对于大多数语言的Redis客户端,如Java的Jedis、Python的redis-py,建议统一接入 redis.service.local:6379,并开启自动重连与连接池配置。
五、高可用性测试与实战验证
我们进行了一轮完整的主节点强制故障测试,数据如下图所示:
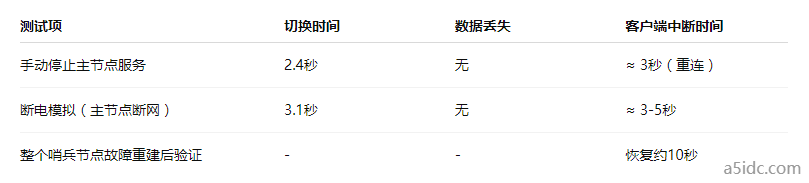
DNS方案的同步速度决定了客户端是否“无感知”,这也取决于本地DNS缓存刷新策略。我们建议业务侧设置 TTL ≤ 5秒 并采用递归查询直达CoreDNS。
六、监控与运维补充方案
部署如下监控与自动化工具提升稳定性:
- Prometheus + Redis Exporter:监控主从状态、命中率、延迟等
- Grafana Dashboard:可视化Redis指标
- 自定义切换告警脚本:通过Slack/邮件通知哨兵切换事件
- 日志系统:ELK Stack,统一采集哨兵与Redis日志
这次在台湾部署Redis高可用集群的经验告诉我,哨兵机制与DNS联动是提升整体稳定性和自动化的关键组合。通过结构分离、网络优化和DNS智能更新,我们实现了在不改动客户端代码的前提下,实现秒级主从切换的能力。未来,我也会继续探索将这一机制引入更复杂的多地域集群架构中,以进一步增强故障隔离与可恢复性。










