
我在参与一个跨国集团的营销数据分析项目时,如何在可控成本内,将日增长量超过3TB的原始日志数据进行近实时的预处理与分析。传统的通用型服务器,在处理复杂查询、ETL流程与模型推演任务时,往往难以满足延迟和吞吐量的要求。为此,我们团队最终选择部署位于香港的数据中心内的硬件加速型服务器,并通过多层优化,显著提升了整体的数据分析效率。以下是我在该过程中积累的完整实操经验。
一、项目背景与性能瓶颈识别
1.1 数据特征分析
- 日增数据量:约3TB
- 数据结构:日志型 + 半结构化(JSON、CSV)
- 分析任务:Hive SQL查询、PySpark处理、XGBoost建模
在初期部署测试中,单台64核心的通用计算服务器执行一次完整的ETL任务耗时约4.5小时,远超目标设定的1小时窗口。分析瓶颈主要集中在:
- 多线程调度不均导致CPU Utilization不稳定;
- I/O频繁,SSD读写成为瓶颈;
- 无法充分利用向量指令集及并行处理能力。
二、香港服务器选型与硬件架构设计
为突破性能瓶颈,我们选择了A5IDC香港数据中心中的以下服务器配置作为主力节点:
2.1 主服务器型号与硬件参数
- CPU:2×Intel Xeon Gold 6348(40核/80线程,支持AVX-512)
- 内存:512GB DDR4 ECC REG,3200MHz
- 加速卡:2×NVIDIA A30 Tensor Core GPU(24GB HBM,每张GPU单精浮点性能达10 TFLOPS)
存储:
- 2×3.84TB NVMe U.2 企业级SSD(Intel D7-P5520)
- 1×8TB SATA 企业级HDD用于冷数据归档
- 网络:2×10Gbps物理独享带宽,CN2 GIA优先路由支持中国大陆快速访问
该配置支持GPU并行计算、内存驻留数据处理和高吞吐I/O调度,是大数据分析中“计算 + 存储 + 传输”三位一体优化的基础。
三、硬件加速落地方法详解
3.1 CPU指令集加速优化
启用了AVX-512向量化编译支持,在Spark环境中通过以下参数激活:
spark.executor.extraJavaOptions=-XX:UseAVX=3
并在编译ETL C++模块时,加入以下编译指令以支持Intel编译器:
-O3 -xHost -march=core-avx512
实际性能提升约15%,尤其是在多列转换与聚合步骤中表现明显。
3.2 GPU加速任务调度(Spark + RAPIDS)
部署了 NVIDIA RAPIDS Accelerator for Apache Spark,核心步骤如下:
GPU驱动与CUDA 11.8环境预配置;
安装 spark-rapids 插件并配置以下参数:
spark.rapids.sql.enabled=true
spark.executor.resource.gpu.amount=1
spark.task.resource.gpu.amount=0.1
spark.plugins=com.nvidia.spark.SQLPlugin
GPU被用于加速SQL转换、Join操作与部分机器学习推演模块(如XGBoost),单任务执行时间从原来的240秒压缩至50秒以内。
3.3 高速存储访问优化
采用NVMe SSD构建Spark临时Shuffle目录,替换HDD传统写盘逻辑:
spark.local.dir=/mnt/nvme/spark-tmp
同时开启I/O并发与零拷贝选项,提升磁盘吞吐与延迟响应。
四、部署结构与运行维护
4.1 集群拓扑结构
部署方案采用“1 Master + 3 Compute Node”结构:
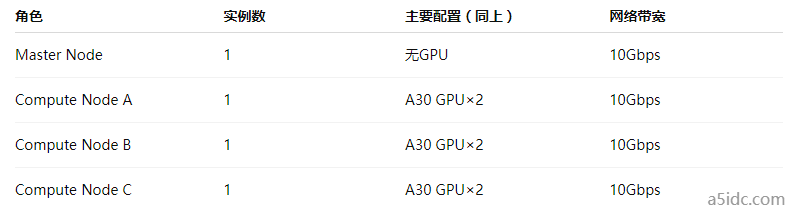
4.2 数据调度与同步
通过Apache Airflow调度GPU ETL任务,配合rsync+inotify机制保障各节点间数据同步精度。元数据与任务日志保存在独立MySQL节点,所有通信走内部SDN私有网络。
五、性能评估与实际收益

不仅满足了实时性需求,也为后续扩容提供了弹性接口,例如支持添加NVIDIA L40 GPU与IB互联网络以支持更大规模的数据处理。
六、未来扩展方向
我们通过本次在香港节点部署的GPU加速型服务器方案,验证了在大数据分析场景下硬件加速的巨大优势。对比传统通用服务器,仅通过合理的架构选型、向量优化与GPU调度策略,性能提升可达3~5倍。未来我们计划引入Intel AMX加速器、构建多区域GPU调度池,以支持更加复杂的机器学习与AI推理任务。










