我在一次香港裸金属服务器上的生产事故中,遇到了一台CentOS 7机器突然内核崩溃重启的情况。系统日志里什么都没留下,dmesg 和 journalctl 都无法回溯到出事时间点。这种“黑洞式”的故障,让我们完全无法定位问题源头。直到我启用了 kdump 机制,才得以捕捉关键内核崩溃转储,从而精准还原问题现场。
下面我详细记录下如何在香港裸金属环境中部署 kdump,确保内核 Panic 时可以可靠生成 crash dump,并结合 crash 工具完成后续分析。
一、kdump 简介与原理说明
kdump 是 Linux 内核的故障转储机制,基于 kexec 技术:当主内核触发崩溃(如 NULL dereference、BUG_ON 等),系统会自动引导一个精简版的第二内核(capture kernel),并在该内核中将主内核的内存状态 dump 到磁盘或网络上,从而为后续调试提供依据。
裸金属服务器上没有虚拟化隔离,一旦 Panic 发生,崩溃风险更高,部署 kdump 是我第一步会启用的防线。
二、安装准备与前置条件检查
我以 CentOS 7 为例,其他 RHEL 系也通用:
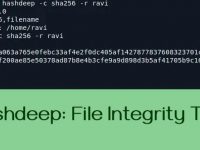
yum install -y kexec-tools crash
确认主机具备以下前置条件:
- 支持 kexec(查看 /proc/cpuinfo 是否支持 kexec)
- 启用了 crashkernel 参数(否则 capture kernel 无法预留内存)
检查当前内核参数:
cat /proc/cmdline | grep crashkernel
如果输出为空,需要追加该参数:
修改 GRUB 配置(以 BIOS 模式为例):
vi /etc/default/grub
添加:
GRUB_CMDLINE_LINUX="crashkernel=256M rhgb quiet"
然后更新 grub:
grub2-mkconfig -o /boot/grub2/grub.cfg
若为 EFI 启动,路径可能为 /boot/efi/EFI/centos/grub.cfg。
最后重启系统生效。
三、配置 kdump 服务
安装完 kexec-tools 后,系统会自动安装默认的 capture kernel 和 initramfs,位于 /boot 目录。
编辑配置文件:
vi /etc/kdump.conf
关键配置:
path /var/crash
core_collector makedumpfile -c --message-level 1 -d 31
default reboot
- path:建议指向本地磁盘较大分区,或远程 NFS/SSH。
- core_collector:使用 makedumpfile 过滤无用页,减少转储文件大小。
- default reboot:crash 后自动重启,适合生产服务器。
也可配置远程 dump 目标:
ssh user@backup-host:/mnt/dumps
启用服务:
systemctl enable kdump.service
systemctl start kdump.service
确认状态:
systemctl status kdump
四、触发内核崩溃测试(仅限测试环境)
确保 kdump 正常工作后,我会先做一次验证:
echo c > /proc/sysrq-trigger
此操作会直接触发内核 panic(前提是 kernel.sysrq=1 开启),系统会重启并生成转储文件。
检查:
ls /var/crash/
可见类似:
/var/crash/127.0.0.1-2025-07-03-15:30/
vmcore
vmcore-dmesg.txt
五、分析 vmcore 文件定位根因
用 crash 工具配合当前 vmlinux 分析:
确保 debug 符号可用:
CentOS 7 下安装调试内核符号:
yum --enablerepo=base-debuginfo install kernel-debuginfo-$(uname -r)
启动分析:
crash /usr/lib/debug/lib/modules/$(uname -r)/vmlinux /var/crash/.../vmcore
常用 crash 命令:
- bt:查看崩溃线程调用栈
- ps:查看崩溃时进程列表
- log:读取内核日志
- kmem -i:查看内存信息
- files:查看打开的文件描述符
这些信息常常能直接定位到触发 panic 的函数或系统调用。
六、线上优化建议与注意事项
crashkernel 预留容量调整
高内存物理机建议设为 crashkernel=512M-1G,避免因内存不足导致 dump 失败。
NFS/SSH dump 时序问题
网络 dump 会拉长恢复时间,如用于极高可用场景,请配合双机 HA 架构。
使用 makedumpfile 压缩
配合 -c 与 -d 31 可将原始 vmcore 从数十 GB 降至几百 MB,加快分析速度。
可选定时清理 dump 文件
/var/crash 文件较大,可定期自动清理,避免磁盘被打爆。
kdump 是我在管理香港裸金属服务器时不可或缺的低层级容错手段。一旦内核级崩溃发生,它是仅存的线索来源。通过合理配置 crashkernel 参数、指定本地或远程转储位置、使用 crash 工具分析,我可以把不可控的 Panic 故障变成可还原、可分析的事件,极大提高了定位和修复内核问题的能力。
部署 kdump 的成本极低,但带来的排障能力是质变的。如果你的生产环境存在不明原因重启,且日志无法记录,强烈建议尽快启用。