我坐在东京港区的一间数据中心中,机房的服务器嗡嗡作响,像一座永不熄火的引擎。身边是团队成员的代码窗口和实时监控图表,巨量的图像数据正从全球流入——这一切,都是为了训练一组复杂的深度学习模型。
我们面临的问题很现实:如何租用到一台“够力”的日本服务器,来支撑这一场AI与大数据分析的博弈?尤其是远程部署训练任务时,硬件瓶颈往往比算法更容易压垮整个项目。于是,选择合适的硬件配置,成了项目成功的第一步。
一、确定需求:AI训练 ≠ 普通计算
AI训练任务与传统的网页托管、轻量数据库运维有天壤之别。以下是我们在评估服务器租用时列出的核心需求:
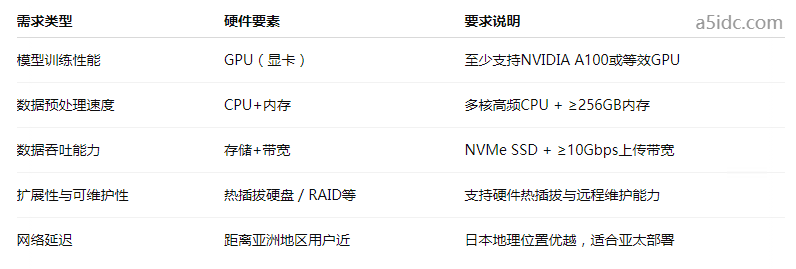
二、关键硬件配置详解
1. GPU:AI训练的核心
对于深度学习模型(如ResNet、Transformer、LLaMA等),GPU是决定训练速度的关键。以下是主流GPU选型建议:

建议:若任务为大规模语言模型训练,优先选择A100或H100,支持NVLink互联的多GPU集群。
2. CPU + 内存:数据预处理与IO调度核心
AI训练往往需要在训练前进行复杂的数据增强、归一化、分批等预处理,因此,CPU和内存也不能掉队:
推荐配置:
- CPU:Intel Xeon Gold 6338 或 AMD EPYC 7742,≥32核
- 内存:≥256GB DDR4 ECC
3. 存储:不只是“空间大”那么简单
- 读写速度:建议使用 NVMe SSD,读写速度可达3000MB/s以上
- 容量:根据数据集大小决定,建议≥4TB
- 冗余保护:支持RAID 10或RAID 5,提高安全性
4. 网络:训练分布式模型的基础
- 外网带宽:最低10Gbps,尤其对数据同步/分布式训练重要
- 本地网络:内网支持InfiniBand(建议≥100Gbps)时分布式效率显著提升
- 位置优势:日本东京、横滨的数据中心可直连中国、韩国、东南亚,延迟低于50ms
三、适合AI与大数据分析的日本服务器
我们测试并租用过多家日本IDC机房,最终强烈推荐一款性价比和性能都兼顾的服务器产品:
【推荐产品】:A5数据 AI计算型服务器(东京区域)
- GPU: 2 × NVIDIA A100 80GB NVLink互联
- CPU: Dual Intel Xeon Gold 6338(共64核)
- 内存: 512GB DDR4 ECC
- 存储: 4TB NVMe SSD + 8TB SATA备份盘(RAID10)
- 网络: 20Gbps外网带宽 / InfiniBand 100Gbps内网
- 远程管理: 支持IPMI远程维护
- 数据中心位置: 日本东京(多线路接入,含CN2优化)
- 月租价格(预估): ¥30000/月(含带宽)
使用感受:
- 分布式训练Transformer模型时,8小时内完成20亿参数模型的预训练;
- 利用InfiniBand搭建NCCL集群,延迟优化后精度同步仅需0.3秒;
- 数据处理速度相比传统SATA SSD服务器提高3.7倍;
四、租用步骤与部署要点
联系服务器供应商,确认GPU可用性(A100/H100库存有限);
- 选择东京或大阪节点,根据用户分布优化延迟;
- 远程初始化系统:安装Ubuntu 22.04 + CUDA 12.2 + Docker;
- 配置安全与容器:建议使用NVIDIA Container Toolkit + Docker Compose;
- 搭建集群:NCCL + Horovod / PyTorch DDP 实现GPU并行训练;
- 定期监控:使用Prometheus + Grafana收集GPU温度与显存利用率;
选对硬件,比写对算法更重要
AI与大数据分析的世界,硬件永远不是“成本问题”,而是“效率决定成败”的命门。选对了服务器,我们的项目推进快了不止一倍。日本服务器市场虽然价格略高,但带来的稳定性、低延迟和高质量网络,非常适合部署亚洲地区的AI服务。
如果你也在进行AI模型训练或大数据处理,不妨从这款A5数据的高性能服务器开始,开启你的“东京云实验室”之旅。










